
Content-aware graphic layout generation aims to automatically arrange visual elements along with a given content, such as an e-commerce product image. In this paper, we argue that the current layout generation approaches suffer from the limited training data for the high-dimensional layout structure. We show that a simple retrieval augmentation can significantly improve the generation quality. Our model, which is named Retrieval-Augmented Layout Transformer (RALF), retrieves nearest neighbor layout examples based on an input image and feeds these results into an autoregressive generator. Our model can apply retrieval augmentation to various controllable generation tasks and yield diverse layouts within a unified architecture. Our extensive experiments show that RALF successfully generates content-aware layouts in both constrained and unconstrained settings and significantly outperforms the baselines.
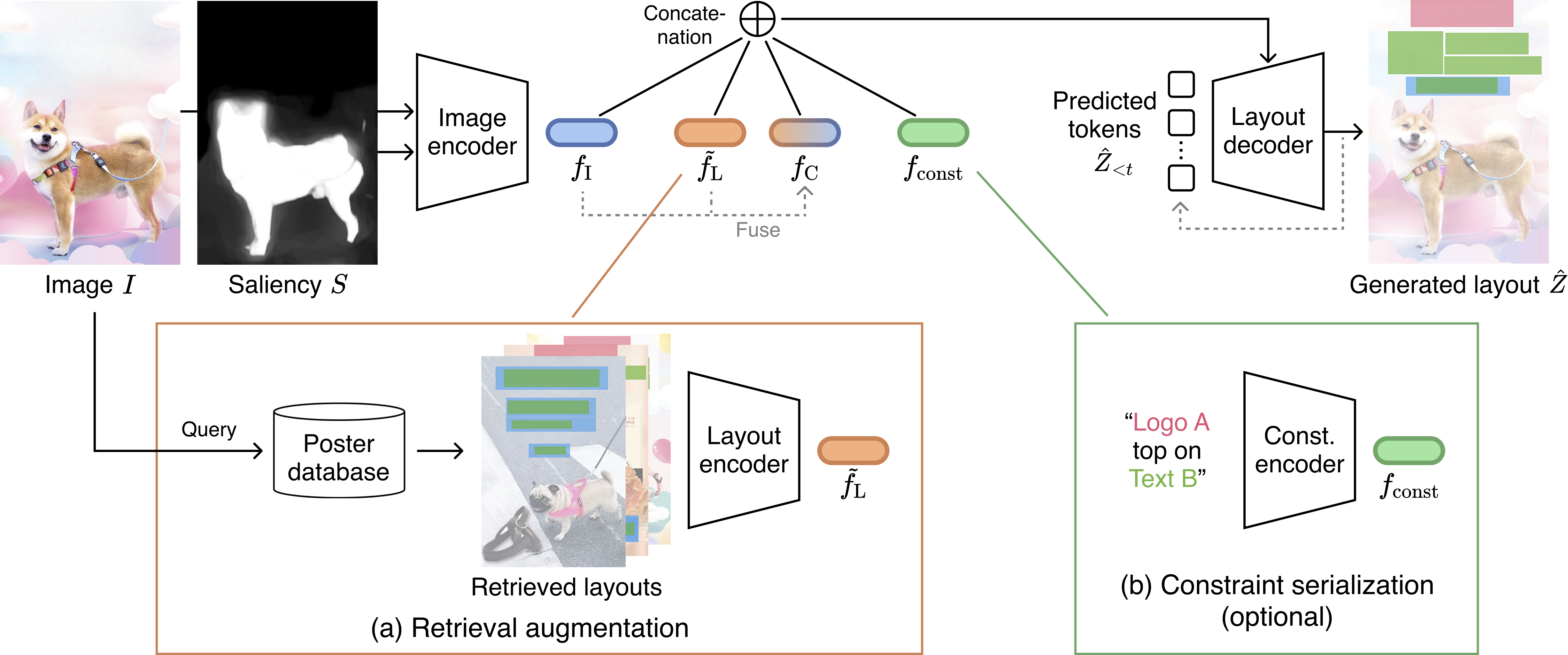
Overview of Retrieval-Augmented Layout Transformer (RALF). RALF takes a canvas image and a saliency map as input, and then autoregressively generates a layout along with the input image. Our model uses (a) retrieval augmentation that incorporates useful examples to better capture the relationship between the image and the layout, and (b) constraint serialization, an optional module that encodes user-specified requirements, enabling the generation of layouts that adhere to specific requirements for controllable generation.
Visual comparison of the proposed method and the baselines, which are CGL-GAN, DS-GAN, LayoutDM, and our proposed Autoreg Baseline. Since LayoutDM is originally designed for content-agnostic layout generation, we extend the model to accept an input image. Autoreg Baseline is equivalent to our RALF without retrieval augmentation.

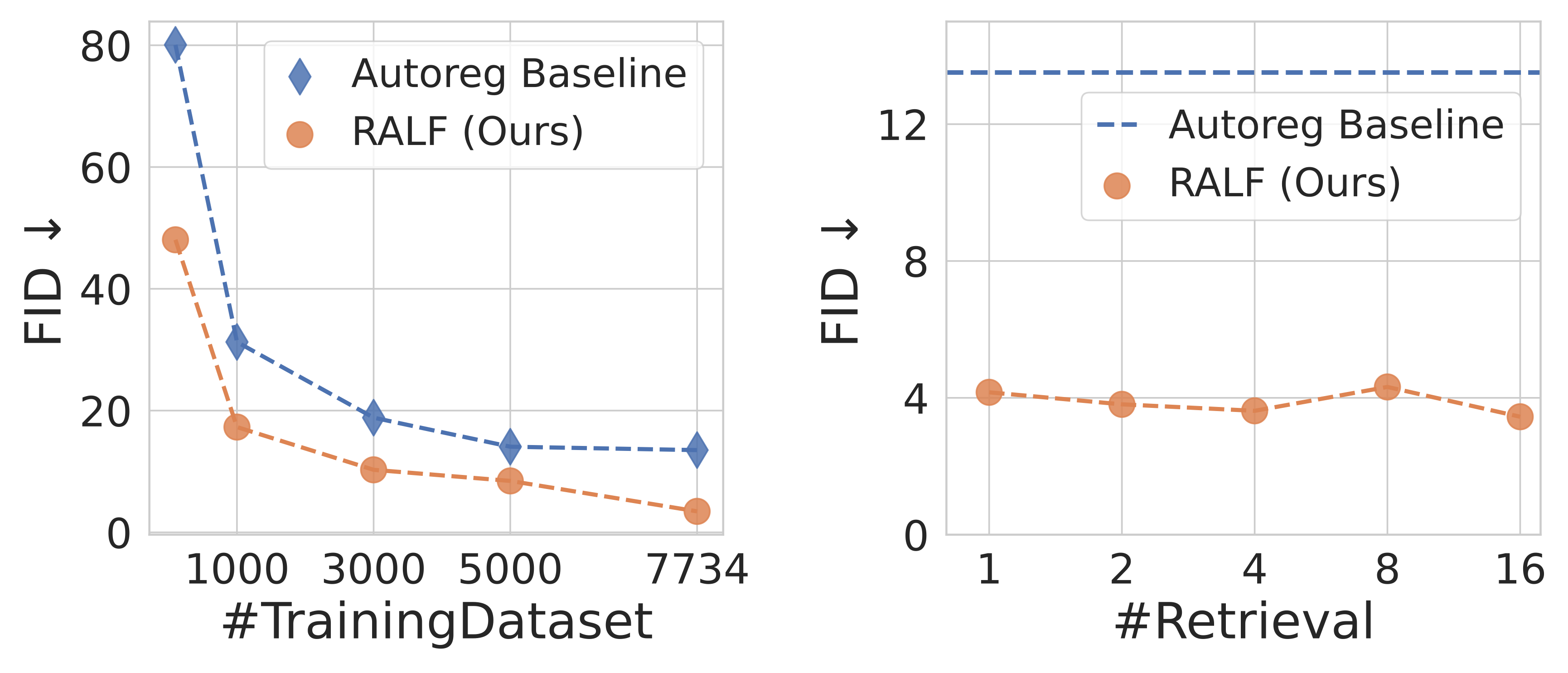
(Left) We show that retrieval augmentation is effective regardless of the training dataset size. Notably, our RALF trained on just 3,000 samples outperforms the Autoreg Baseline trained on the full 7,734 samples in PKU.
(Right) We show that retrieval augmentation is not highly sensitive to the number of retrieved layouts K. Retrieval augmentation significantly enhances the performance even with a single retrieved layout compared to the baseline.
We examine how different K affects the generated results. The result of K=1 shows that the generated layout is similar to the reference layouts, while the result of K=16 shows that a variety of layouts are generated.

@inproceedings{horita2024retrievalaugmented,
title={{Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation}},
author={Daichi Horita and Naoto Inoue and Kotaro Kikuchi and Kota Yamaguchi and Kiyoharu Aizawa},
booktitle={CVPR},
year={2024}
}