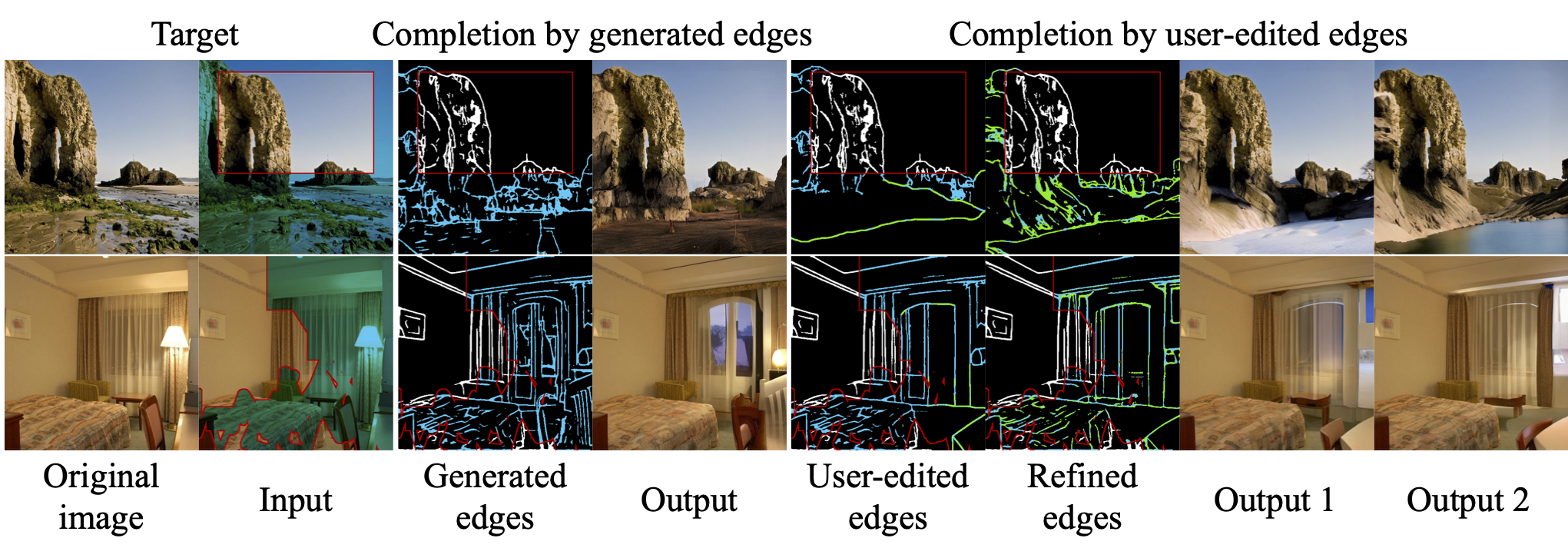
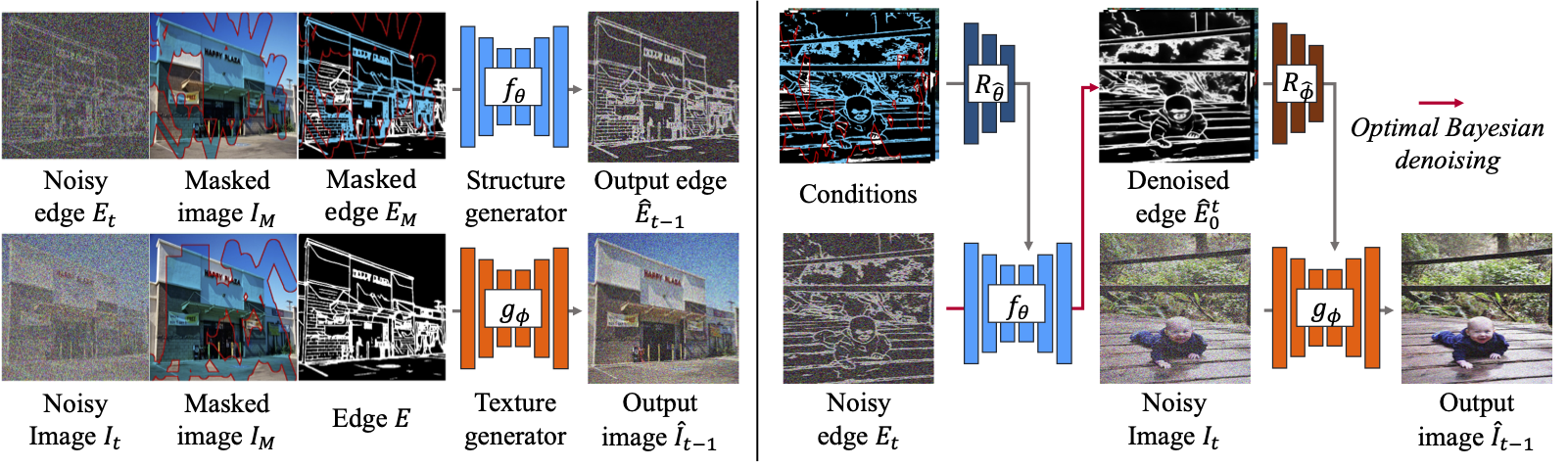
Image completion techniques have made significant progress in filling missing regions (i.e., holes) in images. However, large-hole completion remains challenging due to limited structural information. In this paper, we address this problem by integrating explicit structural guidance into diffusion-based image completion, forming our structure-guided diffusion model (SGDM). It consists of two cascaded diffusion probabilistic models: structure and texture generators. The structure generator generates an edge image representing plausible structures within the holes, which is then used for guiding the texture generation process. To train both generators jointly, we devise a novel strategy that leverages optimal Bayesian denoising, which denoises the output of the structure generator in a single step and thus allows backpropagation. Our diffusion-based approach enables a diversity of plausible completions, while the editable edges allow for editing parts of an image. Our experiments on natural scene (Places) and face (CelebA-HQ) datasets demonstrate that our method achieves a superior or comparable visual quality compared to state-of-the-art approaches.

Language-guided image completion for (a) structure and (b) texture modifications.

@inproceedings{horita2023structureguided
title={A Structure-Guided Diffusion Model for Large-Hole Image Completion},
author={Daichi Horita and Jiaolong Yang and Dong Chen and Yuki Koyama and Kiyoharu Aizawa and Nicu Sebe},
year={2023},
booktitle = {BMVC},
year = {2023},
}